
The Release Nobody Saw Coming (But Everyone Needed)
It's April 16, 2026, and Anthropic just quietly dropped what might be their most impactful model update yet. Claude Opus 4.7 is here, and if you've been watching the AI arms race over the past year, this one feels different. It's not a rebranding exercise. It's not a marketing bump. The numbers are genuinely impressive, and the improvements are in exactly the right places.
We're talking about a model that resolves three times more production software tasks than Opus 4.6, sees the world with triple the visual resolution, and introduces a level of fine-grained control over reasoning that developers have been asking for since the dawn of the frontier model era. Let's get into it.
Vision: Finally, AI That Can Actually See
One of the most underrated improvements in Opus 4.7 is its vision upgrade. Previous Claude models could accept images up to roughly 1 megapixel on the long edge. Opus 4.7 raises that ceiling to 2,576 pixels, approximately 3.75 megapixels. That's more than triple the previous limit.
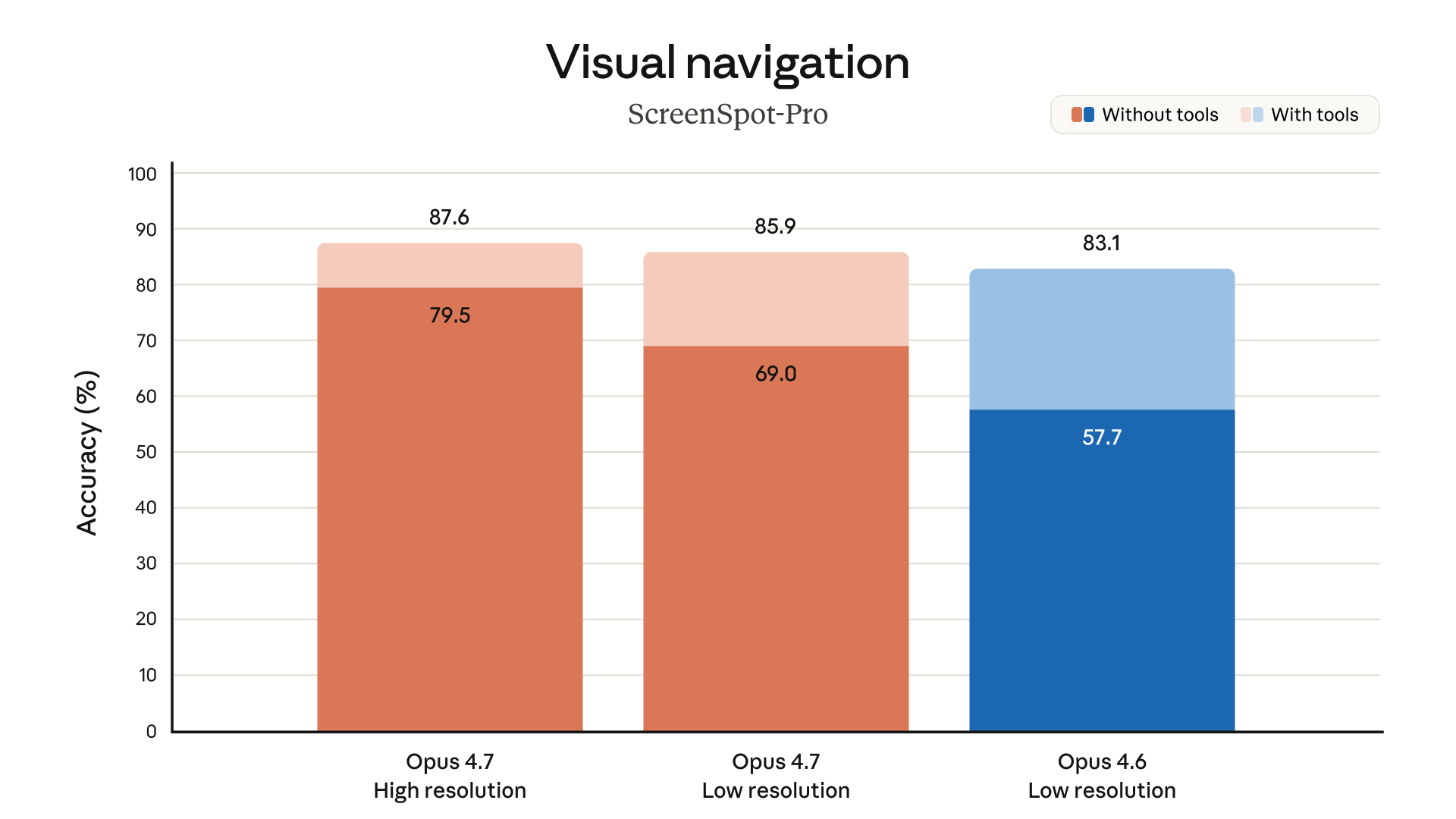
Why does this matter? Because the use cases that actually move the needle -- reading dense technical diagrams, parsing chemical structures, extracting data from screenshots of financial reports -- require resolution. At 1 megapixel, you're squinting. At 3.75 megapixels, you're reading. And if you've ever tried to get an AI to extract structured data from a blurry chart, you'll understand exactly why this upgrade is a big deal.
For computer-use tasks specifically, Opus 4.7 achieves 98.5% visual-acuity performance, compared to just 54.5% for Opus 4.6. That's not an incremental improvement. That's a completely different class of capability.
Coding: The Numbers Don't Lie
This is where Opus 4.7 really flexes. Software engineering has been the battleground for frontier models, and Anthropic has come to this fight prepared.
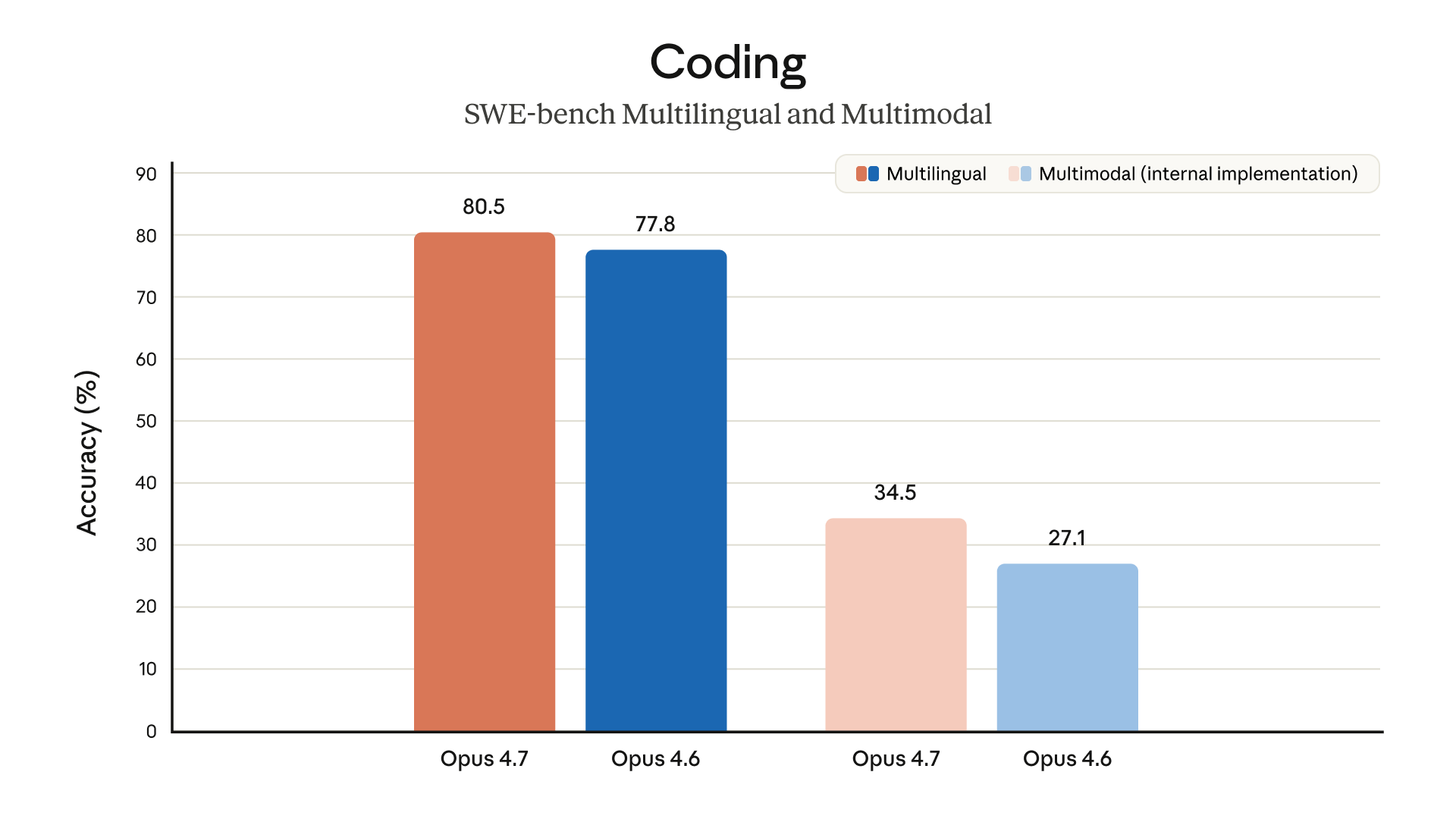
Here's the headline benchmark data:
| Benchmark | Claude Opus 4.6 | Claude Opus 4.7 | Improvement |
|---|---|---|---|
| 93-task coding benchmark | Baseline | +13% resolution rate | +13% |
| Rakuten-SWE-Bench (production tasks) | 1x | 3x | 200% increase |
| CursorBench | 58% | 70% | +12 points |
| Visual-acuity (computer-use) | 54.5% | 98.5% | +44 points |
That Rakuten-SWE-Bench figure deserves a second look. Resolving three times more production tasks isn't just better performance on a curated benchmark -- it's real-world software engineering on real codebases. That's the kind of benchmark result that actually translates to hours saved.
The CursorBench improvement is similarly notable. If you're using Cursor or any AI-assisted coding environment, a jump from 58% to 70% task completion is felt immediately. It's the difference between an AI that almost gets it and one that actually ships.
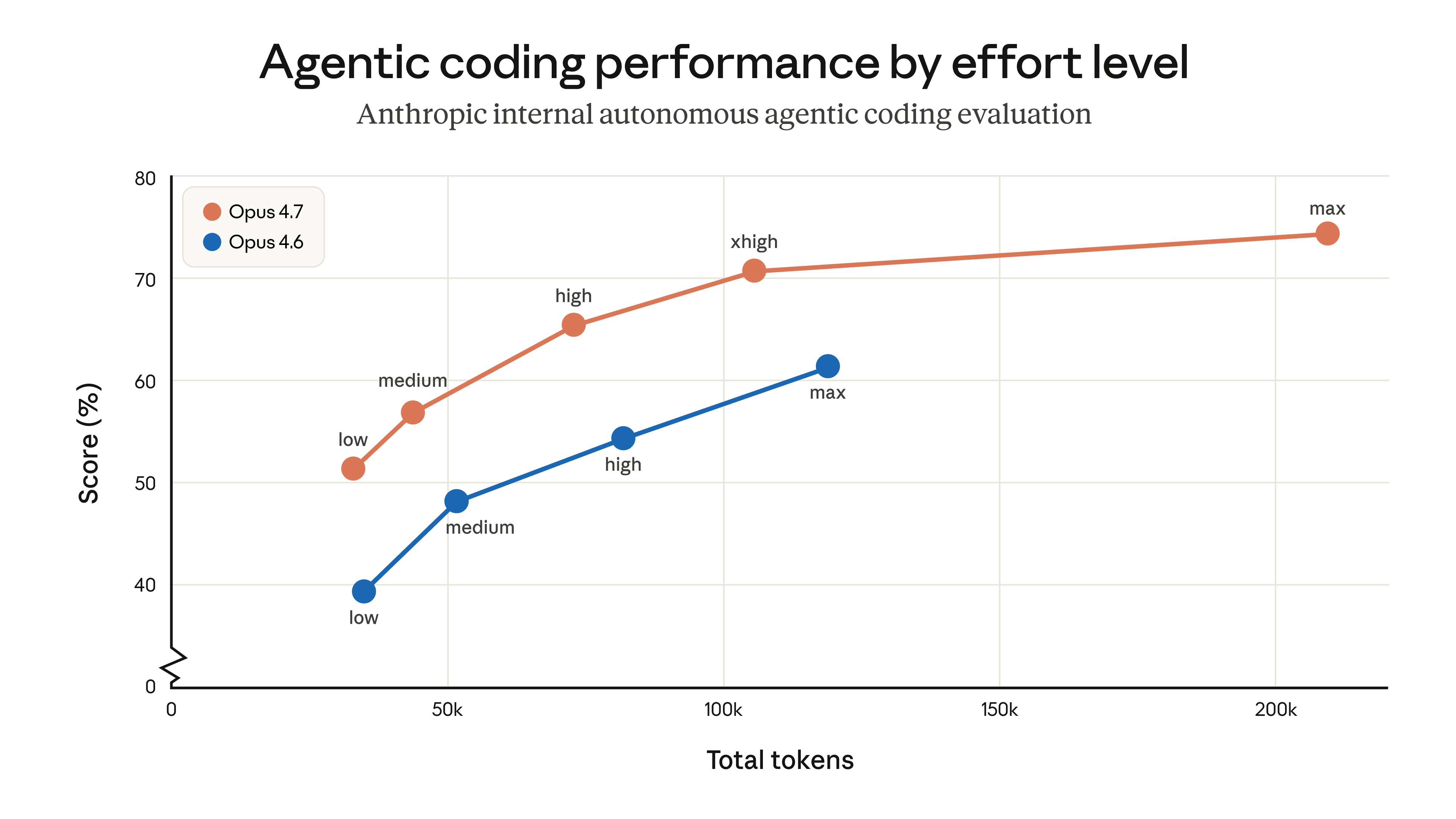
Reasoning on Demand: Introducing xhigh Effort
One of the more interesting additions in Opus 4.7 is a new effort level called "xhigh", sitting between the existing "high" and "max" settings. This gives developers finer control over the reasoning-latency tradeoff.
Think of it like this: sometimes you want a fast answer. Sometimes you want the model to really think. Previously, you jumped straight from "high" to full "max" mode with nothing in between. xhigh fills that gap, letting you extract more reasoning quality without necessarily going to full extended-thinking mode and paying the latency tax.
For agentic workflows that run autonomously over long sessions, this kind of control is invaluable. You can now dial in exactly how much "thinking" a task deserves without overshooting.
Long-Context and Document Work Gets Smarter
Beyond coding, Opus 4.7 shows meaningful gains on long-horizon tasks, multi-session projects where memory and consistency matter.
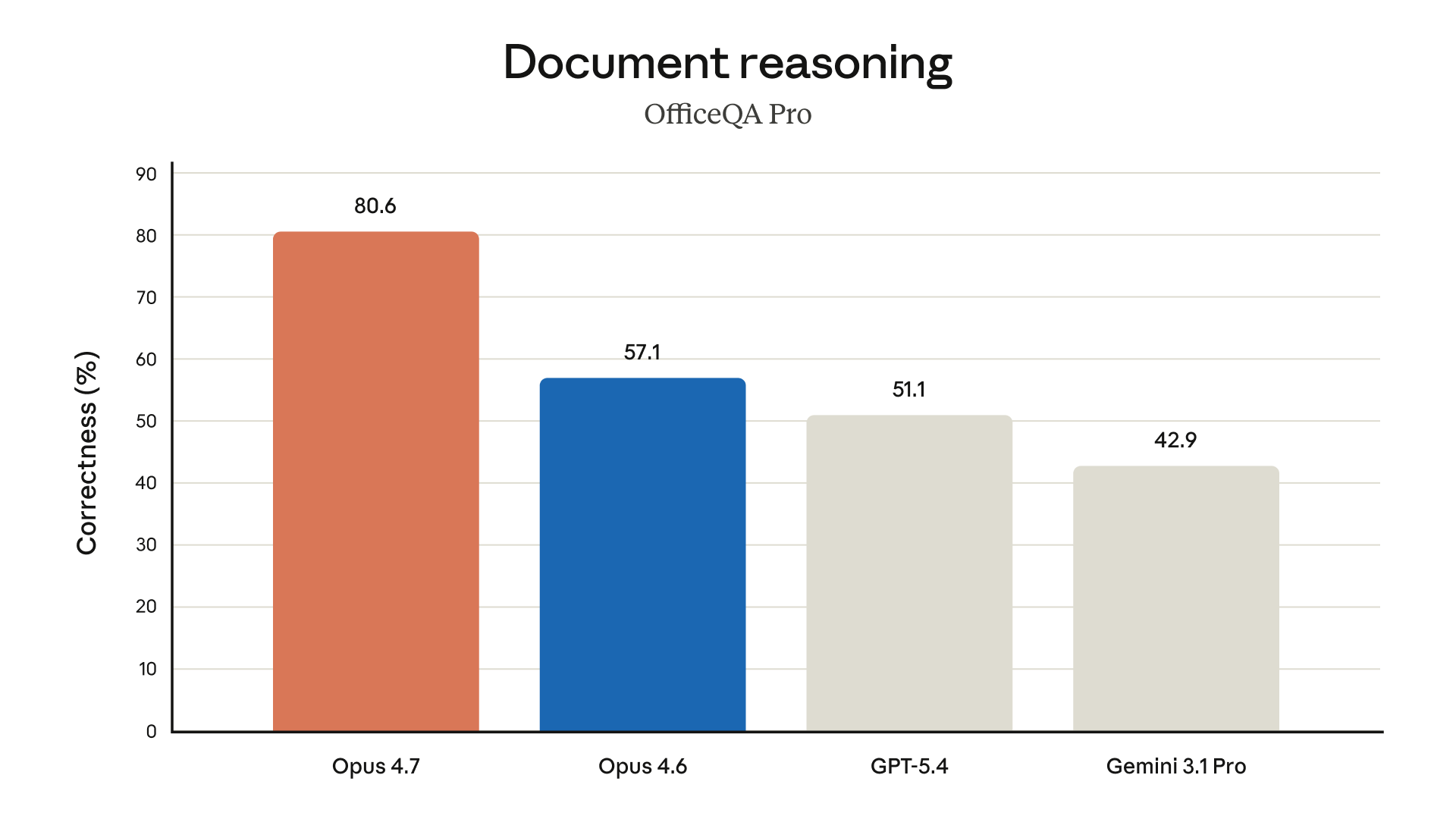
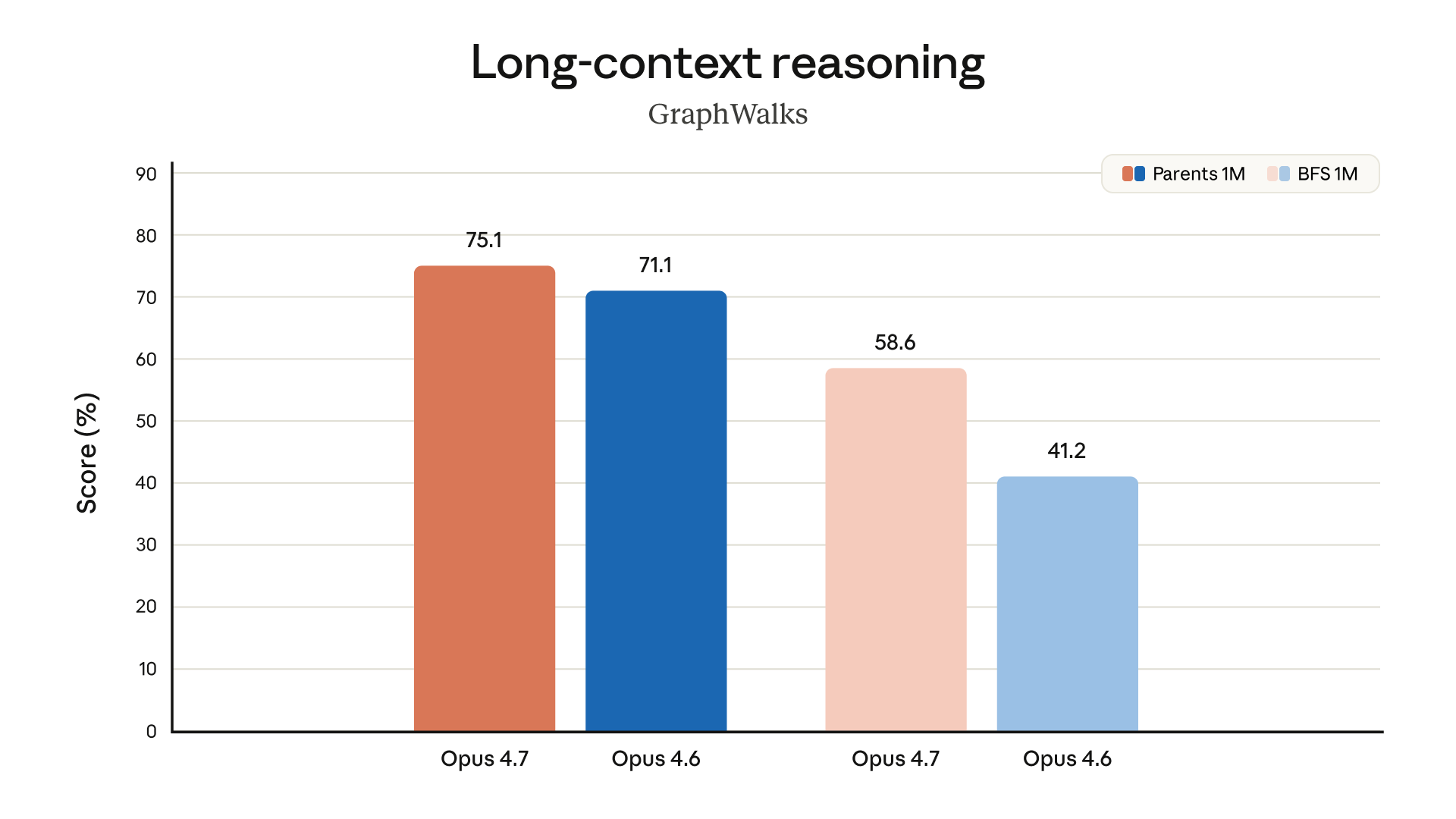
Anthropic also notes improved file system-based memory for multi-session tasks, meaning the model handles information persistence across longer engagements more reliably. For anyone running autonomous research agents or complex document workflows, this is worth paying attention to.
Finance Agent evaluation scores are described as "state-of-the-art," which tracks given the vision and document reasoning improvements. If you're building anything in financial analysis, due diligence, or research automation, this is a meaningful upgrade.
Claude Code Gets a New Trick: /ultrareview
If you're a Claude Code user, Opus 4.7 ships with a new slash command: /ultrareview. This opens a dedicated code review session, separate from your primary coding flow, designed for deep review rather than inline suggestions.
It also extends auto mode to Max plan users, which broadens access to extended-thinking features for a larger chunk of Anthropic's user base.
The Pricing Situation (And the Token Catch)
Here's the good news: pricing hasn't changed. Opus 4.7 remains at $5 per million input tokens and $25 per million output tokens, same as 4.6.
The nuance worth flagging is token usage. Due to an updated tokenizer and enhanced reasoning at higher effort levels, real-world token consumption has increased roughly 1.0 to 1.35x depending on your workload. It's not a price hike, but it's not free either. If you're running high-volume API workloads, you should measure the impact on your actual traffic before cutting over.
Anthropic is also launching task budgets in public beta -- a mechanism for guiding how many tokens a task is allowed to spend. This is genuinely useful for cost management in agentic systems where token spend can balloon unpredictably.
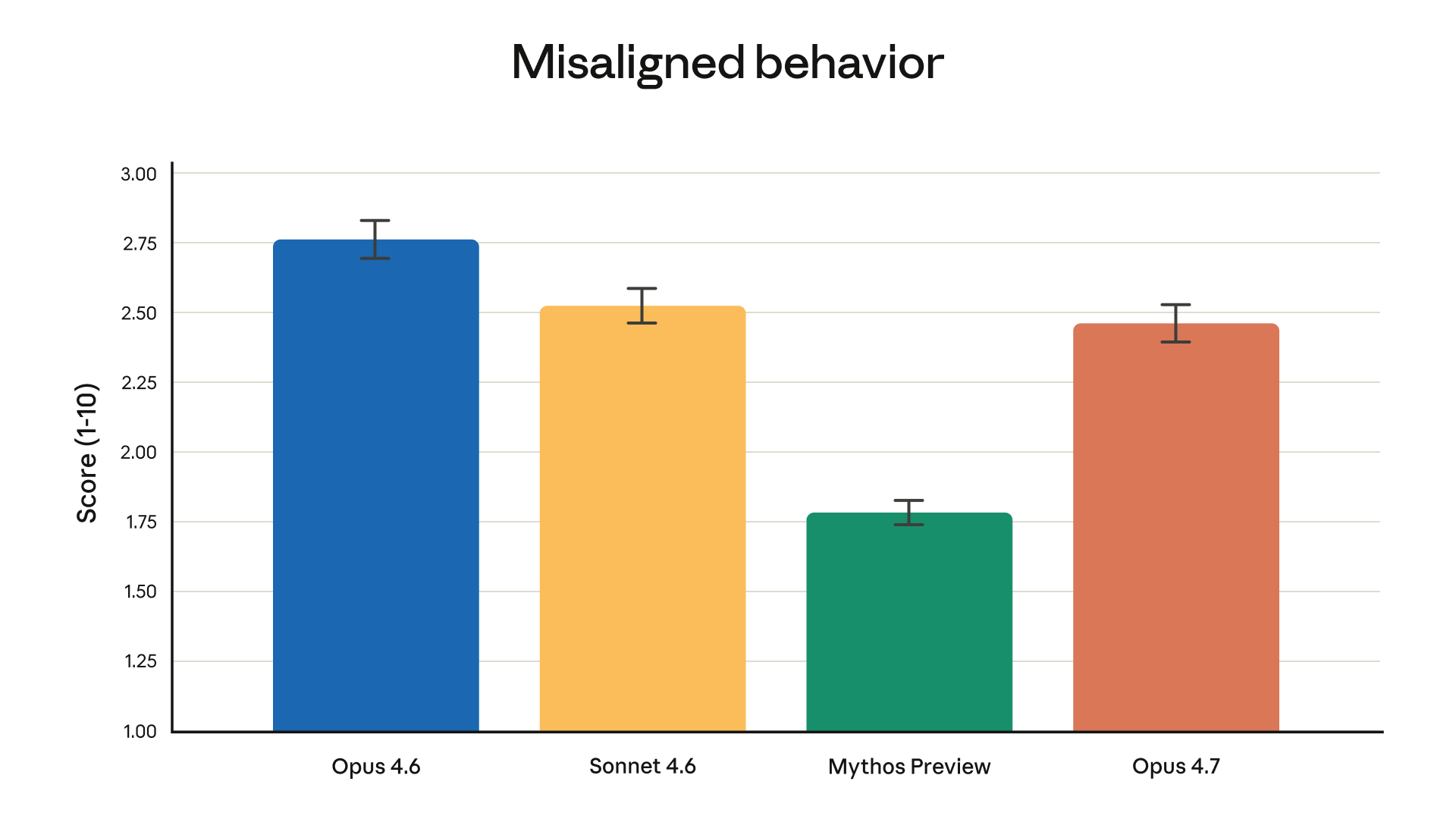
Safety: Consistent Where It Counts
Opus 4.7 maintains a safety profile comparable to 4.6 -- low rates of deception and sycophancy, strong resistance to prompt injection, and improved honesty scores. There's a note that it performs slightly weaker on some harm-reduction advice measures compared to 4.6, but Anthropic is transparent about the tradeoffs, which is the right call.
The broader behavioral audit results tell a consistent story: this is a model that hasn't sacrificed alignment for capability gains.
Where Opus 4.7 Lands in the Landscape
The benchmark comparison chart says a lot about where Opus 4.7 sits relative to the field:
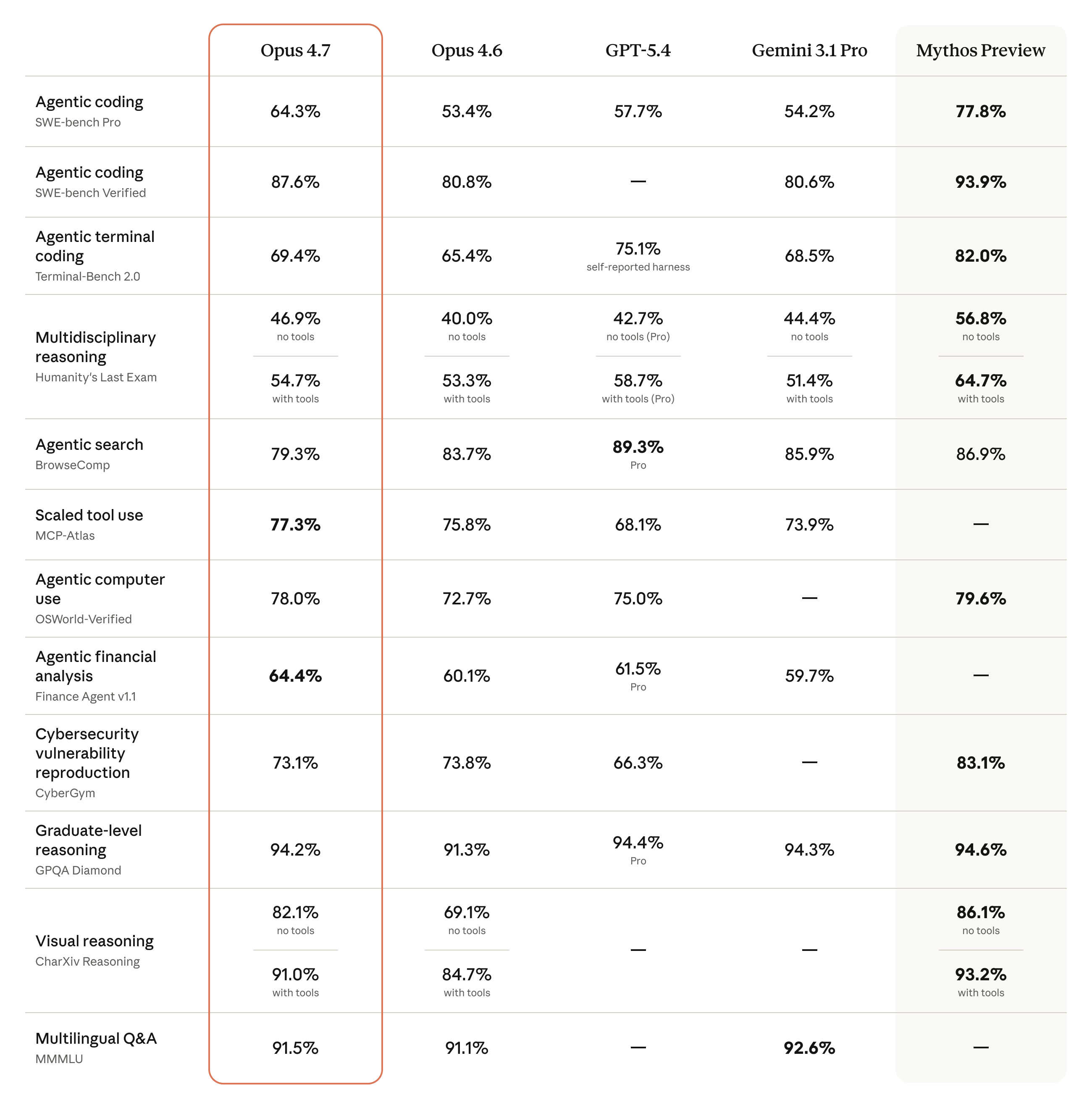
The pattern is clear. Anthropic isn't chasing the headline-grabbing, kitchen-sink model releases. They're making targeted, high-quality improvements to the things that matter most for real-world deployment -- vision fidelity, software engineering depth, and long-horizon consistency. That strategy is paying off.
The Verdict
Claude Opus 4.7 is the kind of release that doesn't need hype. The improvements are specific, measurable, and aimed directly at the use cases where frontier models earn their keep. If you were already on Opus 4.6, upgrading is a no-brainer -- just measure your token usage in staging first. If you've been sitting on the fence about whether the Opus tier is worth it over Sonnet, the coding and vision numbers in 4.7 make that calculation considerably easier.
Anthropic continues to move at a pace that keeps everyone else honest. And if Opus 4.7 is what April 2026 looks like, the rest of the year is going to be interesting.
Opus 4.7 is available now across Claude products, the API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. If you're building on it, I'd love to hear what you're shipping -- reach out.